
Qui est Houda Ferradi ?
Je travaille actuellement en tant que Responsable scientifique en chef chez Dfns. J'ai terminé en octobre 2016 un doctorat en cryptographie et en sécurité de l’information à l'École Normale Supérieure (ENS) de Paris. Après cela, j'ai passé 3 ans en tant que chercheur post-doctorat dans les laboratoires de la plateforme sécurisée NTT à Tokyo. Puis, 2 ans en tant que chercheur au département d'informatique de l'Université polytechnique de Hong Kong (PolyU). Mes recherches actuelles portent sur la cryptographie post-quantique, la sécurité et la confidentialité dans le partage des big data et la technologie blockchain.
Pourriez-vous définir la blockchain simplement pour nos lecteurs ?
Houda pense que la technologie blockchain a suscité une grande attention de la part de l’industrie et du monde universitaire ces dernières années, car elle permet de stocker des données vérifiables de manière fiable et sans avoir besoin d’utiliser un tiers de confiance.
D’une manière générale, une blockchain est une liste croissante de blocs liés par des fonctions cryptographiques et dans laquelle chaque bloc contient un ensemble de transactions. La structure de la blockchain est maintenue par un ensemble de nœuds connectés de manière pair-à-pair (P2P) – c’est ça qui constitue le réseau blockchain.
Les principales propriétés de la blockchain sont les suivantes :
-
Décentralisation : la blockchain est maintenue par un réseau P2P dans lequel tous les nœuds sont identiques et il n’y a aucune autorité centrale qui les gouverne ou qui les contrôle.
-
Transparence : les blocs et les transactions sont visibles par tous les nœuds du réseau et ils sont même publics pour tout le monde.
-
Immuabilité : les données ne peuvent pas être modifiées une fois qu’elles sont stockées sur la blockchain, car les blocs sont générés un par un et reliés de manière sécurisée par des fonctions cryptographiques.
La blockchain est utilisée dans beaucoup de secteurs. On parle de plus en plus de son application avec le big data. Qu’est-ce que le big data exactement ?
Houda m’explique que le terme « big data » est utilisé depuis la fin des années 1990, mais qu’il est rapidement devenu populaire depuis son apparition dans Communications of the ACM en 2009 The pathologies of big data,” Commun. ACM, vol. 52, no. 8, pp. 36–44, 2009. [Online]. Available: https://dl.acm.org/doi/10.1145/1536616.1536632.
En fait, le big data a été défini dès 2001. À cette époque, le big data est généralement défini en fonction du volume, c’est-à-dire qu’il fait référence à un grand volume de données dont la taille dépasse la capacité des outils logiciels couramment utilisés pour capturer, conserver, gérer et traiter les données dans un laps de temps raisonnable.
Par la suite, divers autres « V » ont été ajoutés pour décrire le big data, parmi lesquels on retrouve la variété et la vélocité. La variété du big data fait référence aux différents types ou modalités de données, tandis que la vélocité des données est la vitesse à laquelle les données sont générées et traitées.
Le modèle « 3Vs » a ainsi été formé pour décrire le big data. C’est d’ailleurs ce modèle qui est adopté depuis longtemps par Gartner et de nombreuses autres entreprises telles qu’IBM et Microsoft.
Pourquoi le big data est important pour les entreprises ?
Le big data profite aux découvertes, aux connaissances et aux expériences scientifiques comme la prédiction de la maladie et le traitement thérapeutique.
Ces dernières années, l’analyse des données médicales basée sur l’apprentissage automatique a attiré l’attention des gouvernements, de l’industrie et du monde universitaire. Les approches d’apprentissage automatique exigent un grand nombre de données, qui peuvent difficilement être fournies par une seule organisation médicale.
Par conséquent, l’agrégation des essais cliniques est importante, mais cela peut être réalisé par le partage de big data.
Comment la blockchain est-elle utilisée dans le domaine du big data ?
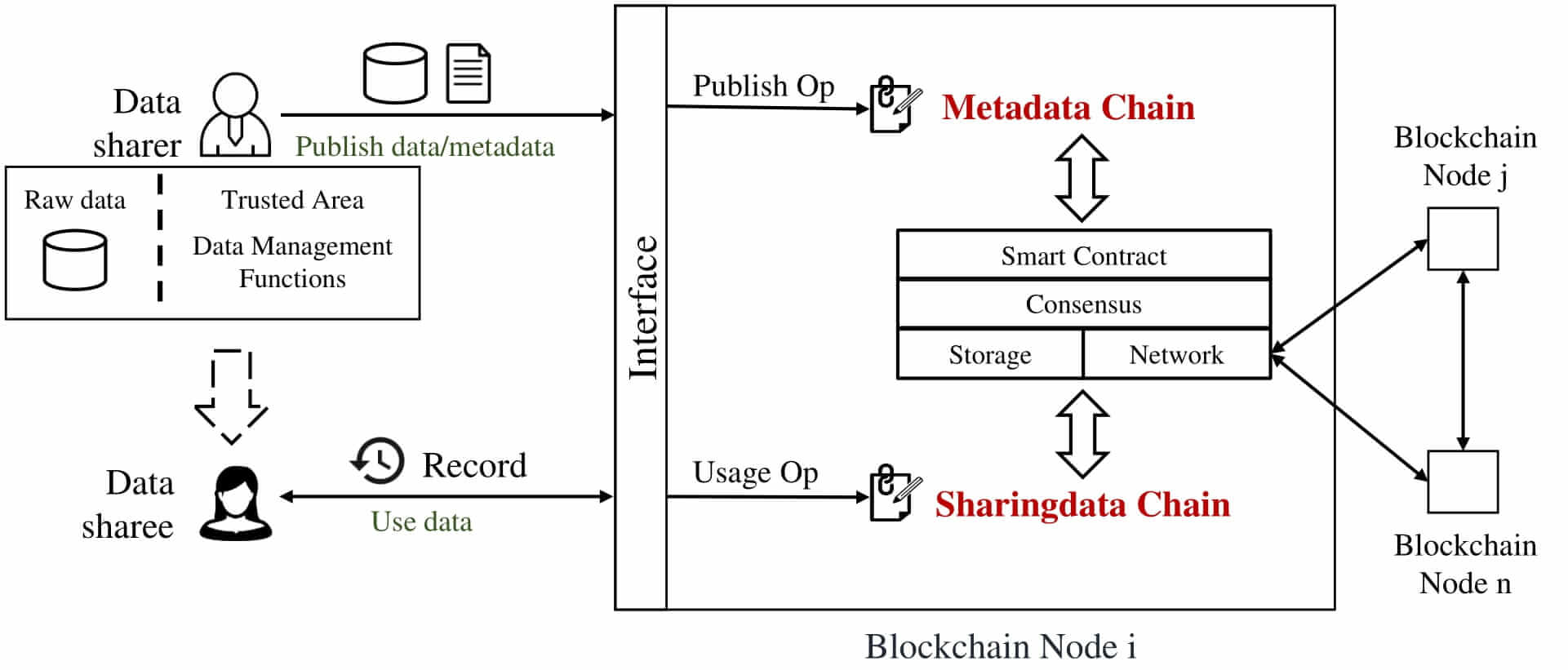
Les personnes ou les entités qui partagent des données ou des métadonnées les publient en utilisant l’interface fournie par les nœuds de la blockchain. Parallèlement, le réseau stocke les données brutes localement et les gère dans une « zone de confiance » comme dans des environnements d’exécution de confiance.
Ceux qui profitent des données partagées utilisent le big data des « partageurs de données » et génèrent des enregistrements de partage. Les opérations de publication et d’utilisation des données sont stockées dans deux blockchains, à savoir la chaîne de métadonnées (metadata chain) et la chaîne de données partagées (sharingdata chain) respectivement.
Houda m’explique alors que les nœuds de la blockchain maintiennent les deux blockchains et permettent l’interaction entre les deux. La chaîne de métadonnées et la chaîne de données partagées utilisent la même infrastructure de blockchain en couches, à savoir la couche des contrats intelligents, la couche de consensus, la couche de stockage et la couche réseau.
La sécurité des données, notamment des informations personnelles, est un enjeu important dans l’exploitation du big data. La blockchain peut-elle permettre une meilleure sécurité du big data ?
Pour Houda, la blockchain peut résoudre les problèmes de confidentialité et d’authenticité dans le partage des big data grâce à ses caractéristiques distinctives de transparence, d’immuabilité et de décentralisation.
D’une part, les big data seront héberées par les propriétaires des données eux-mêmes plutôt que par un tiers de confiance, ce qui évitera toute violation de la vie privée. D’autre part, les données sont vérifiées et confirmées par les nœuds du réseau blockchain, ce qui garantit l’authenticité des données.
À cette fin, la blockchain peut être considérée comme une solution prometteuse pour l’exploitation et le partage des big data.
Qui a dit quoi ? Avec Houda Ferradi – Le mot de la fin
Pour terminer, je demande à Houda quelles sont les perspectives d’avenir de la blockchain dans ce secteur.
De nos jours, la puissance de calcul s’améliore rapidement, ce qui a vraiment favorisé l’apprentissage automatique et l’intelligence artificielle dans les domaines d’application, tels que la vision par ordinateur, le traitement du langage naturel, la conduite autonome, etc.
De plus, les chercheurs ont développé des algorithmes d’apprentissage automatique avancés, comme le deep learning et reinforcement learning. Cependant, le succès de ces algorithmes d’apprentissage automatique dépend fortement de grandes quantités de données à haute variabilité, qui ont été utilisées pour entraîner les modèles à haute précision.
Prenons l’exemple du système de détection des personnes sur Facebook qui utilise 350 millions d’images. Ces données sont riches, mais elles sont souvent sensibles à la confidentialité, en grande quantité, ou les deux. Et parce que les données contiennent des informations privées, les propriétaires des données ne sont pas disposés à les partager, ce qui rend difficile l’obtention d’une grande quantité de données de haute qualité et de grande variété pour obtenir des modèles à haute précision.
Si l’on prend le domaine des soins de santé intelligents, il est nécessaire d’utiliser les analyses pathologiques de plusieurs hôpitaux pour former des modèles à haute précision. Mais les analyses pathologiques contiennent des informations privées sur les patients et pour des raisons de confidentialité et d’intérêt du patient, il est difficile de partager les scans et analyses entre les hôpitaux par exemple – or les scans et analyses d’un seul hôpital ne suffisent pas pour former un modèle à haute précision.
Si nous considérons les scans et analyses comme des données, chaque hôpital peut être considéré comme une île de données précieuse qui n’est pas connectée aux autres. Si le problème des îles de données ne peut pas être résolu efficacement, le développement de l’apprentissage automatique sera limité en raison du manque de données.
Houda m’explique que pour résoudre ce problème, McMahan et al. ont proposé en 2017 l’apprentissage fédéré (FL ou Federated Learning) qui laisse les données d’apprentissage distribuées sur les appareils tout en apprenant via un modèle partagé en agrégeant les mises à jour calculées localement.
Via ce type d’apprentissage [FL], la tâche d’apprentissage est résolue par une fédération souple et ouverte d’appareils participants (clients) qui sont coordonnés par un serveur central.
L’un des principaux avantages de cette approche est le découplage de l’apprentissage du modèle de la nécessité d’un accès direct aux données brutes d’apprentissage et l’absence de stockage central des données, ce qui permet de protéger les informations confidentielles contenues dans les données brutes.
Ces dernières années, de nombreux chercheurs ont utilisé la blockchain pour renforcer l’apprentissage fédéré comme BlockFL proposé par Kim et al. [Hyesung Kim, Jihong Park, Mehdi Bennis et Seong-Lyun Kim. 2019. Blockchained on-device federated learning. IEEE Communications Letters 24, 6 (2019), 1279-1283].
Merci à Houda Ferradi d’avoir participé à cette édition et de nous avoir parlé des opportunités de la blockchain dans le secteur du big data !